
teamtechsoft | Think Future
Forbes'e göre, her gün yaklaşık 2,5 quintilyon bayt veri üretiliyor. Bununla birlikte, bu sayının sonraki yıllarda sürekli artması beklenmektedir (günümüzde depolanan verilerin% 90'ı son iki yıl içinde üretilmiştir)
Büyük Veriyi ilişkisel veritabanlarında depolanan diğer büyük miktardaki verilerden farklı kılan şey onun heterojenliğidir. Veriler farklı kaynaklardan geliyor ve farklı formatlar kullanılarak kaydedildi.
Verileri formatlamak için üç farklı yöntem yaygın olarak kullanılır:
• Yapılandırılmamış = örgütlenmemiş veriler (ör. Videolar).
• Yarı yapılandırılmış = veri sabit olmayan bir biçimde düzenlenmiştir (örn. JSON).
• Structured = veri yapısal bir formatta saklanır (örn. RDBMS).
Büyük Veri üç özellik tarafından tanımlanır:
1. Hacim = büyük miktarda veri nedeniyle, verileri tek bir makinede saklamak mümkün değildir. Hata toleransı sağlamak için verileri birden fazla makinede nasıl işleyebiliriz?
2. Variety = Farklı şemalar kullanılarak biçimlendirilmiş çeşitli kaynaklardan gelen verilerle nasıl başa çıkabiliriz?
3. Velocity = Yeni verileri nasıl hızlı bir şekilde saklayabilir ve işleyebiliriz?
Büyük Veri iki farklı işleme tekniği kullanılarak analiz edilebilir:
• Toplu işlem = genellikle verilerimizin hacmi ve çeşitliliği ile ilgileniyorsak kullanılır. İlk önce gerekli tüm verileri saklıyor ve sonra tek seferde işliyoruz (bu yüksek gecikmeye neden olabilir). Yaygın bir uygulama örneği, aylık bordro özetleri hesaplamak olabilir.
• Akış işleme = genellikle hızlı tepki süreleriyle ilgileniyorsak kullanılır. Verilerimizi alındığı anda işleriz (düşük gecikme süresi). Bir uygulama örneği, bir banka işleminin sahte olup olmadığını belirleyebilir.
Büyük Veriler, MapReduce, Spark, Hadoop, Pig, Hive, Cassandra ve Kafka gibi farklı araçlar kullanılarak işlenebilir. Bu farklı araçların her birinin, şirketlerin bunları nasıl kullanmaya karar verebileceğini belirleyen avantaj ve dezavantajları vardır
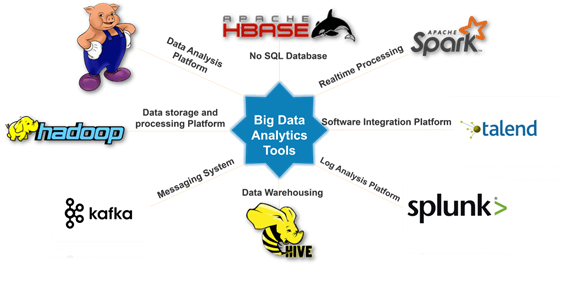
Şekil 1: Büyük Veri Araçları [2]
Büyük Veri Analizi, günümüzde pek çok şirket tarafından piyasa trendlerini tahmin etmek, müşteri deneyimlerini kişiselleştirmek, şirketlerin iş akışını vb. Hızlandırmak için yaygın olarak kullanılmaktadır.
Çok miktarda veri ile çalışırken ve kaynaklarımız tükendiğinde, iki olası çözüm vardır: yatay veya dikey ölçekleme.
Yatay ölçeklemede bu sorunu aynı kapasitede daha fazla makine ekleyerek ve iş yükünü dağıtarak çözüyoruz. Dikey ölçeklendirme kullanıyorsanız, bunun yerine makinemize daha fazla hesaplama gücü ekleyerek ölçekleniriz (örn. CPU, RAM).
Dikey ölçeklendirmenin, yatay ölçeklendirmeye göre yönetimi ve kontrolü kolaydır ve göreceli olarak küçük boyutlu bir sorunla çalışırken etkin olduğu kanıtlanmıştır. Bununla birlikte, yatay ölçeklendirme genellikle büyük bir sorunla çalışırken dikey ölçeklendirmeden daha ucuz ve daha hızlıdır.
MapReduce, yatay ölçeklendirmeye dayanmaktadır. MapReduce'da Paralelleştirme için Big Data ile uğraşmayı kolaylaştıran bir bilgisayar kümesi kullanılmıştır.
MapReduce'da giriş verilerini alıyor ve birçok bölüme ayırıyoruz. Her parça daha sonra işlenmek üzere farklı bir makineye gönderilir ve sonunda belirtilen bir grup işlevine göre toplanır .
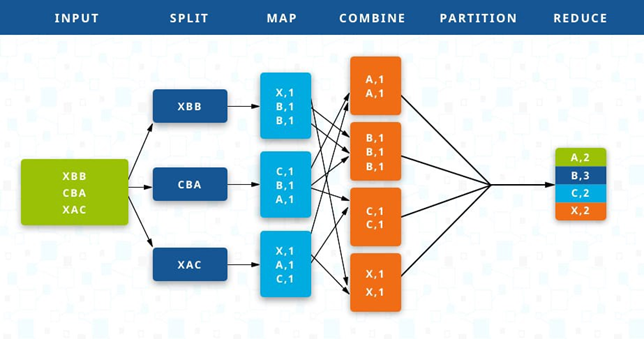
Şekil 2: Eylem sırasında MapReduce [3]
Apache Spark çerçevesi, MapReduce'un bir geliştirmesi olarak geliştirilmiştir. Spark'ı rakiplerinden farklı kılan özellik, MapReduce'dan 100 kat daha hızlı olan yürütme hızıdır (orta düzey sonuçlar saklanmaz ve her şey bellekte yürütülür).
Apache Spark yaygın olarak kullanılır:
1. Saklanan ve gerçek zamanlı verilerin okunması.
2. Çok miktarda veri (SQL) önceden işleyin.
3. Makine Öğrenimi kullanarak verileri analiz edin ve grafik ağları işleyin.
Apache Spark, Python, R ve Scala gibi programlama dilleriyle kullanılabilir. Spark'ı çalıştırmak için bulut tabanlı uygulamalar yaygın olarak kullanılır; Amazon Web Servisleri, Microsoft Azure ve Veritabanları (ücretsiz bir topluluk sürümü sağlar) gibi.
Spark kullanırken, Büyük Veriler Esnek Dağıtılmış Veri Kümeleri (RDD'ler) kullanılarak paralelleştirilir. RDD'ler, Apache Spark'ın orijinal verilerimizi alan ve farklı kümeler (işçiler) arasında bölen en temel soyutlamasıdır. RRD'ler hataya dayanıklıdır; bu, çalışanlardan herhangi birinin başarısız olması durumunda kaybolan verileri kurtarabilecekleri anlamına gelir.
RDD'ler, Spark'ta iki tür işlemi gerçekleştirmek için kullanılabilir: Dönüşümler ve Eylemler (Şekil 4).
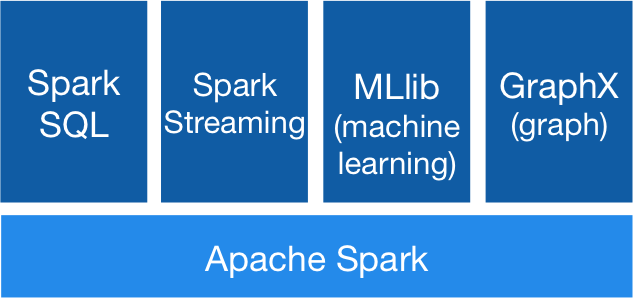
Şekil 4: Apache Spark İş Akışı [5]
Dönüşümler, RDD'lerden yeni veri kümeleri oluşturur ve sonuç olarak bir RDD döndürür (örneğin, anahtar işlemlerle eşleme, filtreleme ve azaltma). Tüm dönüşümler tembeldir, bir eylem çağrıldığında sadece bir kez yapılır (bir yürütme haritasına yerleştirilir ve daha sonra bir Eylem çağrıldığında gerçekleştirilir).
Bunun yerine analiz sonuçlarımızı Apache Spark'dan almak ve Python / R uygulamamız için bir değer döndürmek için (örneğin, toplama ve alma işlemleri) eylemler kullanılır.
Anahtar / değer çiftlerini Spark ürününde saklamak için, RDS Çiftleri kullanılır. Çift RDD'ler, bir demet içinde depolanan iki RRD tarafından oluşturulur. Birinci anahtar elemanı, anahtar değerlerini saklamak için kullanılırken ikincisi, değer elemanlarını (anahtar, değer) depolamak için kullanılır.
Hadoop, Java'da yazılmış ve çok miktarda veri üzerinde işlem yapmak için kullanılabilecek bir dizi açık kaynaklı programdır. Hadoop ölçeklenebilir, dağıtılmış ve hataya dayanıklı bir ekosistemdir. Hadoop'un ana bileşenleri [6]:
• Hadoop YARN = iş yükünü bir makineler kümesi üzerine ayırarak sistemin kaynaklarını yönetir ve zamanlar.
• Hadoop Dağıtılmış Dosya Sistemi (HDFS) = hataya dayanıklı, yüksek verim ve yüksek bant genişliği sunan, kümelenmiş bir dosya depolama sistemidir. Ayrıca, herhangi bir veri türünü mümkün olan herhangi bir biçimde saklayabilir.
• Hadoop MapReduce = verileri bir veritabanından yüklemek, biçimlendirmek ve kantitatif analiz yapmak için kullanılır
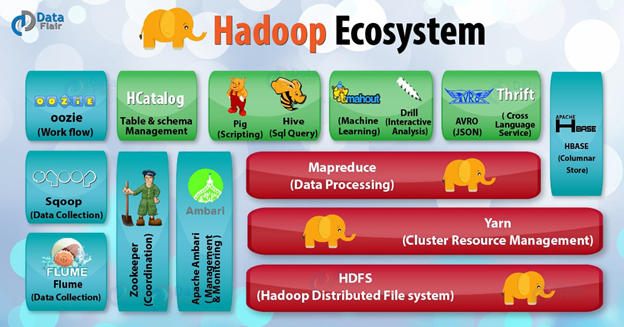
Şekil 5: Hadoop Ekosistemi [7]
Hadoop'un bazı uygulama örnekleri şunlardır: arama (ör. Yahoo), kütük işleme / Veri ambarı (ör. Facebook) ve Video / Görüntü Analizi (ör. New York Times).
Hadoop geleneksel olarak MapReduce'u geniş ölçekte kullanıma sunan ilk sistem olmuştur, ancak bugünlerde Apache Spark daha yüksek uygulama hızı sayesinde birçok şirketin tercih çerçevesidir.
Büyük Veri terimi başlangıçta bir sorunu tanımlamak için kullanıldı: aslında işleyebileceğimizden daha fazla veri üretiyoruz. Yıllarca süren araştırma ve teknoloji gelişmelerinden sonra, Büyük Veri artık bunun yerine bir fırsat olarak görülmektedir. Big Data sayesinde Yapay Zeka ve Derin Öğrenme alanındaki son gelişmeler mümkün olmuş ve makinelerin birkaç yıl önce gerçekleştirmesi imkansız gibi görünen görevleri yerine getirebilmiştir.